











These days, the vector database scene is looking like California during the 1850s gold rush. Blink twice, and you’ll find a new one popping up on the block. Some of the biggest names are Milvus, Pinecone, and KDB.ai, and while some of these companies are heavily branded, ridiculously-funded juggernauts, others vying for their place at the top are buzzing GitHub repositories growing only via word of mouth.
Our favorite project of this budding collection is Chroma. But do they have what it takes to secure a foothold at the top of the vector database food chain? And why is this such a now-or-never lunge for the finish line?
With branding reminiscent of simplistic titans like Google, Chroma seems to be taking the right strides toward being the Postgres of vector databases. In short, Chroma could presumably become the default vector database that developers learn when entering the AI space - if they play their cards right.
Of course, in a busy ecosystem, there may be many winners. Even among relational databases, Postgres is still strongly rivaled by MySQL and MariaDB (fun fact, those latter projects are named after the developer’s daughters, My and Maria). And the vector database space is full of very well-funded, growing projects. So the question remains: Can Chroma capture the crown?
First, why are vector databases popping off?
Unless you’re entirely off the grid, you’ve likely heard of the AI hubbub bubbling across the tech capitals (and the Internet, at large). The wave was sparked by OpenAI’s GPT-3, a large language model (LLM) that proved very effective. Many tech commentators would remark that AI has replaced NFTs as developers and investors’ new favorite thing. Unlike cartoon monkeys, LLMs have already been integrated into real business and consumer-facing applications like Notion, Retool, Adobe, and Copilot by Command AI. (My boss might’ve made me add one of those.)
A common misconception, however, is that these production applications are just integrating with an AI company’s API and calling it a day. In reality, that’s only half of the equation; the other half is efficiently storing data that can be used to fine-tune the model’s results. This is where embeddings come in.
What are embeddings?
An embedding is basically an AI-branded term for vectors. Embeddings are just an array of numbers, e.g., [4.32, 2.32, 4.34, ...] that represent a string’s values in the context of the model. For a generic LLM, the embeddings of “Julie likes Hondas” and “Jane loves Maseratis” should be close to each other but distant from the embeddings of “Too many dogs are eating chocolate in Central Park”. If you want to dive deeper into embeddings, check out the breakdown inside our LangChain guide.
Of course, databases have been able to store arrays for ages. Postgres has a native ARRAY type, while NoSQL databases such as MongoDB can natively store arrays and even objects. Vector databases like Chroma can not only automatically compute the embeddings, but they can also perform search against embeddings efficiently.
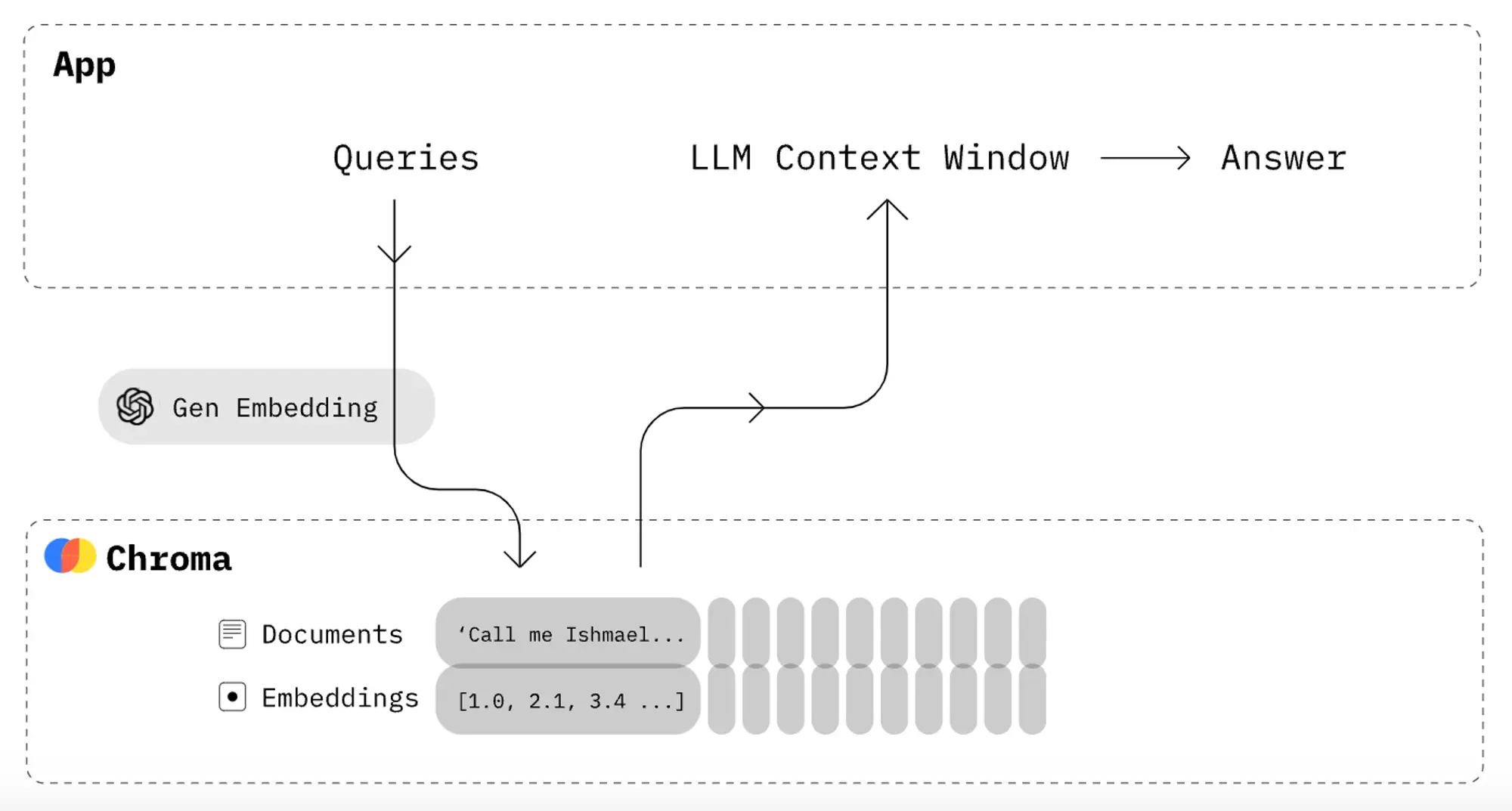
In other words, if I enter the string "Simon adores Mazdas" and ask for two similar strings, it’ll efficiently retrieve the Julie and Jane examples. This makes Chroma and its counterparts efficient solutions for AI applications that need to store training data.
What is Chroma, specifically?
Chroma is an open-source vector database that directly integrates with popular LLMs, including the open-source all-MiniLM-L6-v2 LLM produced by the SentenceTransformers project. With Chroma, developers can easily calculate and save embeddings, and then efficiently search for data with similar embeddings.
Chroma natively supports other popular models like OpenAI’s GPT, Cohere’s flagship models, Google’s PaLM, and Anthropic’s Claude. I initially found this quite peculiar to Chroma and the vector database space at large; open-source native integrations with proprietary products were common. I would’ve expected those connectors to be optional plug-ins. But after reaching out to Jeff Huber, Chroma’s founder (and a very nice guy), he made a great case for the design pattern: It makes for a better developer experience and is less than 500 lines of code strewn together in one file.
At the end of the day, Chroma is still a business. An open-source producing business, but still a business. It has raised over $18M from venture capital. Specifically, it brands itself as a COSS (commercial open-source software) company. I’ll dive more into that later, but this structure allows for Chroma’s core product to be open source while also allowing the company to generate revenue via products targeting larger companies, such as managed infrastructure and enterprise-grade features. Today, most open-source databases (including Milvus and Weaviate) are also COSS projects.
How does Chroma work?
A Chroma database is a series of collections. Collections are groupings of entities. Each collection has a specified embedding function, which is either a custom function or a third-party library.
If you, like me, grew up building applications via relational databases such as MySQL, a collection is like a table and an embedding function is like a trigger or materialized view and, for those familiar with non-relational databases, such as MongoDB, a table is like a collection, and an embedding function is like a trigger or materialized view. Exploring the differences between relational vs non-relational databases can provide further insights into how these concepts translate across different systems.
Chroma allows developers to insert and update data, auto-calculating the embedding values for the developer. Alternatively, the developer could pre-calculate the embedding values and store them if they wish.
The real benefit of Chroma, however, is in retrieval. Chroma’s query function allows developers to query the closest entries to a provided set of embeddings (or an input). This is similar to MySQL’s string-match feature LIKE. The search space can also be condensed by using Chroma’s filters, allowing developers to ask questions such as “Which products are the most similar to this product?”
For example, a documentation product might create a collection and then ingest content into Chroma by using Chroma’s add function.
import { ChromaClient } from 'chromadb'
const client = new ChromaClient();
const collection = await client.createCollection({name: "documents"});
await collection.add({
ids: ["document_1", "document_2", "document_3"],
metadatas: [{user: "Carl"}, {user: "Karen"}, {user: "Carl"}],
documents: ["Lorem Ipsum", "Dolurum Sanctorum", "Noctum Markum"],
});
After, they can use Chroma’s query function to perform a vector search.
await collection.query({
nResults: 1,
where: {"user": "Carl"},
queryTexts: ["Nactum"],
})
This will find the closest entry using Chroma’s distance function. Chroma’s distance function can also be configured, which is what defines the math on how to compare embeddings. A common distance function is squared L2 distance (sum((Ai-Bi)^2)) which serves as Chroma’s default. Other common options are inner product (1.0 - sum(Ai*Bi)) or cosine distance (1.0 - sum(Ai*Bi) / sqrt(sum(Ai*Ai) * sum(Bi*Bi))). The ideal distance function is a matter of what data was ingested; for instance, cosine similarity is typically used to calculate the similarity between two text paragraphs.
How is Chroma configured?
Chroma has two modes: an in-memory mode and a persistent client/server mode. Chroma’s in-memory mode is similar to a database like Redis—and like Redis, it’s extremely fast and great for testing. Meanwhile, the persistent client/server is preferable for production and is designed to scale.
Chroma’s support for both is a very smart mode. It appeals to both hobbyists who can install and use Chroma very quickly and engineers from real companies needing to use Chroma in production.
Currently, Chroma can only be self-deployed. However, the Chroma team is focused on creating a managed offering to help developers use Chroma without worrying about deployment.
What does Chroma integrate with?

Chroma integrates with a wide range of LLMs, including OpenAI’s GPT, Cohere’s flagship models, Google’s PaLM, and Hugging Face’s many models. Chroma also recently announced an integration with LangChain, a popular framework that seamlessly integrates with major language models. Chroma’s integration with LangChain is very ORM-like, where data structures can be easily stored without exiting the main flow of logic.
Why Chroma is a great project
It would be incorrect to claim that Chroma is a super mature project or even the furthest along amongst vector databases. It is very early. Like v0.4.11 early. It has some commercial deployments—like Perfect—but it’s early adoption-wise too.
But Chroma is going to be a winner. The product is showing amazing signs of promise that are reminiscent of Postgres’s early days. Here are three reasons why:
1. Chroma’s mission is very broad
There are hundreds of ways to partition classes of databases; one of the most important is splitting the database space between general-purpose and niche.
Recently, niche databases have been earning themselves a lot of press. The most obvious is Snowflake, a closed-source proprietary database that can handle semi-structured data. Snowflake is a product many developers know but few developers use. That’s because Snowflake—like its counterparts such as AWS Redshift or Google BigQuery—is specifically designed for enterprise users.
Niche databases aren’t just for big-bucks spenders. For instance, SQLite is very much a niche database for smaller, hobbyist projects.
General-purpose databases, meanwhile, are the databases helpful to companies and projects at all sorts of stages. Often, learning how to use these are considered basic schools. The obvious two that come to mind are MySQL and Postgres, but I’d even throw MongoDB in there. These databases are great for hobbyists and production teams, and while the tapped set of features differs per database, they are part of the same system.
Chroma, in their own words, aspires to be a general-purpose database. They state on their website that their mission is to “need to be available to a new developer just starting in ML as well as the organizations that scale ML to millions (and billions) of users.” This broad mission, especially for a budding space, is a big deal. It helps maximize the number of users who care about Chroma’s development, kicking up the value of online chatter and search-indexed guides. Even more importantly, a broad mission helps steer projects to build generalizable, un-opinionated designs that withstand any changing needs of the industry.
Postgres debuted in 1996. It remains one of the most leveraged databases today. That’s because of its design, a design that Chroma seems to carry.
2. Chroma’s ironed-out open-source philosophy
Open-source are two cherished words of any developer. Many successful projects that retain mainstream adoption today, including databases, are open-source. The best examples are Postgres, MySQL, and MongoDB (the last a tad controversial, more on that later).
Granted, databases don’t need to be open-source to be successful. Snowflake, AWS Redshift, and Google BigQuery are massive, profitable projects that don’t have a shred of open-source DNA in their design. But they are also all enterprise products—they don’t gain the same public, widespread adoption of open-source counterparts. In the vector database field, the closed-source analog is Pinecone.
Chroma isn’t the only open-source vector database, but what’s great about Chroma is that it feels like an open-source project first and a company second. It’s built by a small team in Potrero Hill, San Francisco, founded by Jeff Huber and Anton Troynikov. But they also have real community contributors credited on their website. For instance, their Ruby, Java, Go, C#, Rust, Elixir, and Dart libraries are actually managed by community developers.
Chroma classifies itself as a COSS (commercial open-source software). Eventually, Chroma will likely describe itself as “open-core” once they start building proprietary features not included in their open-source version. This split isn’t inherently a bad thing, but can be if Chroma decides to start moving basic features behind paywalls.
Thankfully, Chroma explicitly defines their open-source values on their website, that indicates this won’t be an issue. These values include:
- Chroma being built on a common open-source standard
- Chroma scaling a viable business model that caters towards commercial buyers to support Chroma financially long-term
- Chroma uses a public standard on what features are kept in open-source over proprietary products. They define this standard as Gitlab’s buyer-based open-source model, where any feature that a hobbyist would actually use should always remain open-source.
Chroma pledging to stick to a common open-source standard is important. Recently, many popular open-source projects have switched from a widely accepted open-source standard to a more “source-available” standard that puts commercial restrictions on how the code can be distributed. These include MongoDB, that switched to a more niche SSPL license, and Elastic, which switched to their own Elastic license. This led to much backlash from the open-source community and has stoked more scrutiny around open-source projects. Chroma’s dedication to stick to a wildly-accepted open-source standard is noteworthy.
3. Chroma’s priorities
A big piece of open-source is optics—open-source companies are made or broken by their relationships with their community. And Chroma’s relationships with their community are top-notch. They have a very active Discord (been snooping around it for a few days) and a genuinely engaged community.
The website’s limited brand also helps. Chroma’s website looks very different from other vector database products, even open-source ones. Chroma doesn’t really have a brand outside of its tri-color logo; its website emulates a Notion document more than a typical SaaS company with $18M in funding.
I’m not insulting them here. This is a good thing. Open-source companies that adopt marketing-first brands are prioritizing the “C” in COSS more than the “OS”. An argument can be made that securing financial stability is important, but often it drones out the core product’s development. For Chroma, building for the common developer is a priority.
Of course, it’s worth mentioning that Chroma still does have many noteworthy investors, including Astasia Myers, Naval Ravikant, the Altmans, and founders of Notion, Replit, Vercel, and CockroachDB. Some of their investors also hail from MongoDB, a company that scaled via open-source (before admittedly changing licenses).
Closing Thoughts
Chroma is a BFD in the vector database space. It’s showing early promise of being the leading vector database of the future, and its core open-source values are very community-friendly.












